
Im sich rasant entwickelnden Bereich der künstlichen Intelligenz hat sich DeepSeek als führender Anbieter für die Entwicklung fortschrittlicher Sprachmodelle etabliert. Insbesondere der innovative Ansatz der DeepSeek-V2-Serie hat die Grenzen der Effizienz und Leistung erweitert und bietet modernste Lösungen für eine Vielzahl von KI-gesteuerten Anwendungen.
Architektonische Innovationen
Die DeepSeek-Modelle zeichnen sich durch mehrere wichtige architektonische Verbesserungen aus.
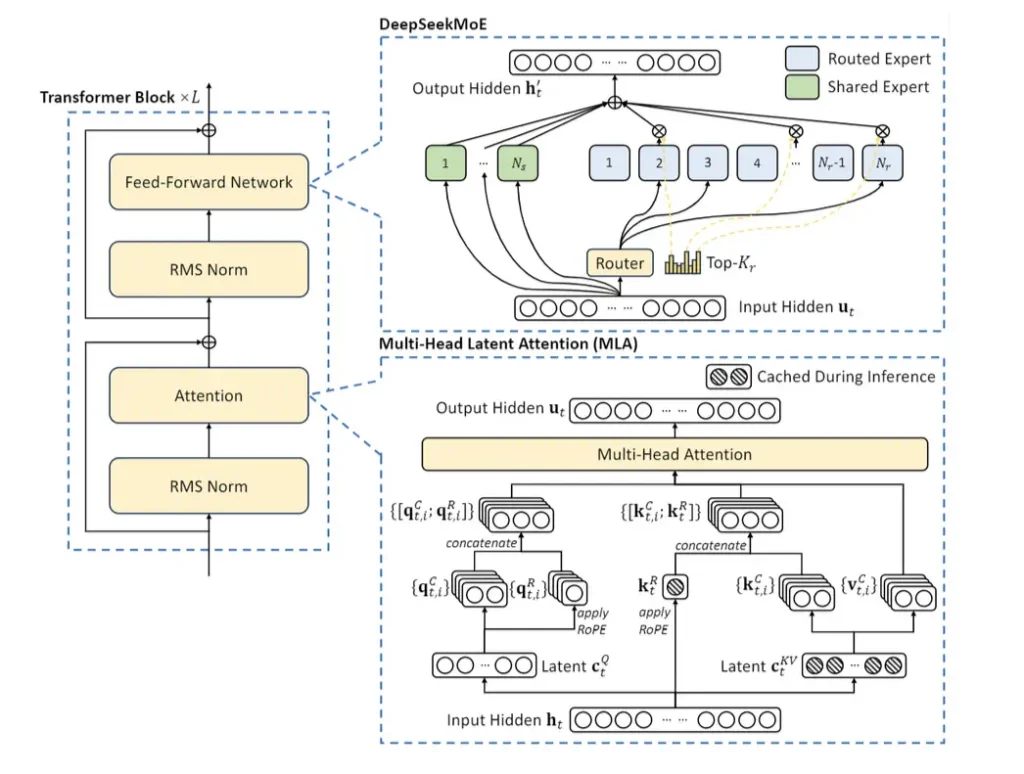
- Multi-Head Latent Attention (MLA): Diese Technik komprimiert Schlüssel-Wert-Paare, wodurch Engpässe bei der Inferenzzeit reduziert werden und eine schnellere Verarbeitung ermöglicht wird.
- Mixed Expert (MoE): Dies ermöglicht die selektive Aktivierung von Parametern pro Token, wodurch die Recheneffizienz erheblich optimiert wird und gleichzeitig eine robuste Leistung gewährleistet bleibt.
- Erweiterte Kontextlänge: Das DeepSeek-V2-Modell kann erweiterte Kontextlängen verarbeiten, wodurch es komplexere Abfragen bearbeiten und konsistentere Ergebnisse generieren kann.
Das DeepSeek-Modell verstehen
DeepSeek ist eine Sammlung großer Sprachmodelle, die für herausragende Leistung bei einer Vielzahl von KI-Aufgaben entwickelt wurden, darunter natürliche Sprachverarbeitung (NLP), Codierung und mathematisches Denken. Diese Modelle verfügen über eine Mixed-Expert (MoE)-Architektur und Feinabstimmungstechniken, die die Effizienz und Skalierbarkeit erheblich verbessern.
DeepSeek-R1
DeepSeek hat seine Inferenzmodelle der ersten Generation vorgestellt: DeepSeek-R1-Zero und DeepSeek-R1. DeepSeek-R1-Zero ist ein Modell, das ohne vorherige überwachte Feinabstimmung (SFT) mithilfe von groß angelegter Verstärkungslernen (RL) trainiert wurde und eine hervorragende Leistung bei der Inferenz zeigt. Durch RL zeigt DeepSeek-R1-Zero auf natürliche Weise eine Vielzahl leistungsstarker und interessanter Schlussfolgerungsverhalten. DeepSeek-R1-Zero steht jedoch vor Herausforderungen wie endlosen Wiederholungen, Lesbarkeitsproblemen und Sprachvermischung.
Um diese Probleme zu beheben und die Inferenzleistung weiter zu verbessern, hat DeepSeek DeepSeek-R1 eingeführt, das Cold-Start-Daten vor dem RL einbezieht. DeepSeek-R1 erreicht eine Leistung, die mit OpenAI-o1 in Mathematik-, Code- und Schlussfolgerungsaufgaben vergleichbar ist. Um die Forschungsgemeinschaft zu unterstützen, hat DeepSeek DeepSeek-R1-Zero, DeepSeek-R1 und sechs aus DeepSeek-R1 extrahierte hochdichte Modelle auf Basis von Llama und Qwen als Open Source zur Verfügung gestellt. DeepSeek-R1-Distill-Qwen-32B übertrifft OpenAI-o1-mini in verschiedenen Benchmarks und erzielt neue Spitzenergebnisse für hochdichte Modelle.
Nach dem Training: Groß angelegtes Reinforcement Learning auf dem Basismodell
DeepSeek wendet Reinforcement Learning (RL) direkt auf das Basismodell an, ohne sich auf Supervised Fine-Tuning (SFT) als Vorstufe zu verlassen. Dieser Ansatz ermöglicht es dem Modell, Gedankenketten (CoT) zur Lösung komplexer Probleme zu erkunden, was zur Entwicklung von DeepSeek-R1-Zero geführt hat.
DeepSeek-R1-Zero demonstriert Fähigkeiten wie Selbstverifizierung, Introspektion und die Generierung langer CoT und markiert damit einen wichtigen Meilenstein für die Forschungsgemeinschaft. Bemerkenswert ist, dass dies die erste offene Forschungsarbeit ist, die zeigt, dass die Schlussfolgerungsfähigkeiten von LLMs rein durch RL ohne SFT verbessert werden können. Diese bahnbrechende Leistung ebnet den Weg für zukünftige Fortschritte in diesem Bereich.
DeepSeek hat eine Pipeline für die Entwicklung von DeepSeek-R1 eingeführt. Diese Pipeline umfasst zwei RL-Stufen, die darauf abzielen, verbesserte Inferenzmuster zu entdecken und diese an menschliche Präferenzen anzupassen, sowie zwei SFT-Stufen, die als Grundlage für die Inferenz- und Nicht-Inferenzfähigkeiten des Modells dienen. DeepSeek ist überzeugt, dass diese Pipeline die Entwicklung überlegener Modelle ermöglichen wird, die einen Beitrag für die Branche leisten können.
Modelldestillation
DeepSeek hat gezeigt, dass es die Inferenzmuster größerer Modelle in kleinere Modelle verdichten kann und dabei eine bessere Leistung erzielt als Inferenzmuster, die durch RL unter Verwendung kleinerer Modelle entdeckt wurden. Das Open-Source-Modell DeepSeek-R1 und seine API werden der Forschungsgemeinschaft dabei helfen, kleine Modelle weiter zu verdichten.
Mithilfe der von DeepSeek-R1 generierten Inferenzdaten hat DeepSeek mehrere in der Forschungsgemeinschaft weit verbreitete Modelle auf den neuesten Stand gebracht. Die Bewertungsergebnisse zeigen, dass die extrahierten kleineren Modelle mit hoher Dichte bei Benchmarks eine hervorragende Leistung erzielen. DeepSeek stellt der Community Open-Source-Zugriff auf 1,5 Milliarden, 7 Milliarden, 8 Milliarden, 14 Milliarden, 32 Milliarden und 70 Milliarden Checkpoints zur Verfügung, die aus den Serien Qwen2.5 und Llama3 extrahiert wurden.
Bewertung von DeepSeek-R1
Die Bewertung von DeepSeek-R1 misst die Leistung des Modells anhand verschiedener Benchmarks. Dieses Modell verwendet eine Mixed-Expert-Architektur (MoE) und aktiviert 37 Milliarden Parameter von insgesamt 671 Milliarden. In der Kategorie Englisch erzielte DeepSeek-R1 90,8 bei MMLU (Pass@1) und 84,0 bei MMLU-Pro (EM). Mit 92,2 bei DROP (3-Shot F1) übertraf es andere Modelle und erreichte 83,3 bei IF-Eval (Prompt Strict). Bei GPQA-Diamond (Pass@1) erzielte es 71,5 und bei SimpleQA (Correct) 30,1. Die Punktzahl bei FRAMES (Acc.) beträgt 82,5 und bei AlpacaEval2.0 (LC-Winrate) wurden 87,6 Punkte erzielt.
In code-bezogenen Benchmarks zeigte DeepSeek-R1 mit 92,3 bei ArenaHard (GPT-4-1106) und 65,9 bei LiveCodeBench (Pass@1-COT) eine hohe Leistung. Es belegte Platz 96,3 bei Codeforces (Perzentil) und erzielte 2.029 Punkte bei Codeforces (Bewertung). Diese Ergebnisse belegen die hervorragende Leistung von DeepSeek-R1 sowohl bei der englischen Sprachverständnis- als auch bei den Codierungsaufgaben und bestätigen seine Effektivität in mehreren KI-Bewertungsbenchmarks.

Auswahl des richtigen Modells
- DeepSeek-R1-Zero und DeepSeek-R1: Ideal für groß angelegte Anwendungen, die hohe Rechenleistung und lange Kontextfenster erfordern.
- DeepSeek-R1-Distill-Modell: Ideal für schnellere Inferenz, geringeren Speicherverbrauch und spezifische Aufgaben wie mathematisches Denken und Codegenerierung.
- Qwen-basiertes Destillationsmodell: Ideal für Aufgaben mit umfangreichen mathematischen und logischen Denkprozessen.
- Llama-basiertes Destillationsmodell: Geeignet für allgemeines Sprachverständnis und das Befolgen von Anweisungen.
DeepSeek-V2
DeepSeek-V2 ist ein fortschrittliches Mixed-Expert (MoE)-Sprachmodell, das herausragende Leistung bei kostengünstigem Training und effizienter Inferenz bietet. Bei insgesamt 236 Milliarden Parametern werden nur 21 Milliarden Parameter pro Token aktiviert, wodurch ein optimales Gleichgewicht zwischen Recheneffizienz und Modellleistung gewährleistet ist.
DeepSeek-V2 übertrifft seinen Vorgänger DeepSeek 67B in der Gesamtleistung bei mehreren Aufgaben und Benchmarks und reduziert gleichzeitig die Rechenkosten erheblich. Es erzielt eine Reduzierung der Trainingskosten um 42,5 %, eine Reduzierung der KV-Cache-Anforderungen um 93,3 % und eine Steigerung des maximalen Generierungsdurchsatzes um das 5,76-fache, was es zu einem leistungsstarken und dennoch ressourceneffizienten Modell macht.
DeepSeek-V2 wurde auf einem großen und vielfältigen Datensatz von hoher Qualität mit 8,1 Billionen Tokens trainiert. Dieses groß angelegte Vortraining wurde durch „Supervised Fine-Tuning (SFT)“ weiter verbessert, das die Antworten des Modells verfeinert und die Übereinstimmung mit der menschlichen Absicht verbessert, sowie durch „Reinforcement Learning (RL)“, das die Entscheidungsfähigkeiten optimiert und die Qualität der Freiformgenerierung verbessert. Die Bewertungsergebnisse belegen die herausragende Leistung des Modells sowohl bei Standard-KI-Benchmarks als auch bei realen Freiform-Aufgaben und bestätigen seine Effektivität in einem breiten Anwendungsspektrum.
Am 6. Mai 2024 wurde DeepSeek-V2 offiziell veröffentlicht und setzte damit einen neuen Maßstab für MoE-basierte KI-Modelle. Am 16. Mai 2024 wurde DeepSeek-V2-Lite als schlankere Version mit Schwerpunkt auf Effizienz angekündigt. Mit seiner bahnbrechenden Architektur und seinem effizienzorientierten Design hat sich DeepSeek-V2 als hochmodernes Sprachmodell etabliert, das hohe Leistung bei deutlich reduzierten Rechenkosten bietet.
Modellarchitektur
DeepSeek-V2 verfügt über modernste architektonische Innovationen, um ein kostengünstiges Training und eine optimierte Inferenzleistung zu gewährleisten.
- Multi-Head Latent Attention (MLA): Dieser Mechanismus nutzt eine Low-Rank-Key-Value-Union-Komprimierung, um Key-Value-Cache-Engpässe während der Inferenz zu beseitigen und so die Inferenz-Effizienz deutlich zu verbessern.
- DeepSeekMoE für Feed-Forward-Netzwerke (FFNs): Durch die Nutzung eines leistungsstarken Mixed-Expert (MoE)-Frameworks ermöglicht DeepSeekMoE das Training leistungsfähigerer Modelle bei gleichzeitig reduzierten Rechenkosten.
So erhalten Sie Zugriff auf DeepSeek-V2
DeepSeek-V2 ist ein hochmodernes Mixed-Expert (MoE)-Sprachmodell, das auf mehreren Plattformen und Schnittstellen verfügbar ist. Für Forscher, Entwickler oder Unternehmen, die seine leistungsstarken KI-Funktionen integrieren möchten, gibt es mehrere Möglichkeiten, auf DeepSeek-V2 zuzugreifen und es zu nutzen.
Offizielle Website
Der einfachste Weg, auf DeepSeek-V2 zuzugreifen, ist über die offizielle Website DeepSeek.com. Hier finden Sie detaillierte Informationen zu den Funktionen, Updates und Anwendungsmöglichkeiten des Modells. Die Website bietet auch Zugriff auf Dokumentationen und Anwendungsbeispiele, die den Benutzern helfen, die Funktionen zu verstehen.
Hugging Face-Plattform
DeepSeek-V2 ist auf Hugging Face verfügbar, einer weit verbreiteten Plattform für KI- und Machine-Learning-Modelle. Auf Hugging Face können Benutzer Modelle interaktiv testen, vorab trainierte Versionen herunterladen und diese mithilfe der bereitgestellten APIs in ihre eigenen Projekte integrieren. Entwickler können Modelle mithilfe des Hugging Face-Ökosystems auch für bestimmte Aufgaben optimieren.
GitHub-Repository
Für Entwickler, die sich für die Architektur und Implementierung des Modells interessieren, sind der Quellcode und zugehörige Ressourcen für DeepSeek-V2 auf GitHub verfügbar. Das Repository enthält wichtige Dokumentationen, Trainingsdaten und Konfigurationseinstellungen, die eine umfassende Anpassung und Bereitstellung ermöglichen.
API-Zugriff
Unternehmen und Entwickler können DeepSeek-V2 über die DeepSeek-API in ihre eigenen Anwendungen integrieren. Diese API bietet Zugriff auf die Funktionen des Modells und ermöglicht so eine nahtlose Bereitstellung in verschiedenen Umgebungen, z. B. Chatbots, Content-Generierung und Codierungsunterstützung. Lesen Sie zunächst die offizielle API-Dokumentation, um sich über die Authentifizierung, Anfrageformate und Best Practices für die Verwendung zu informieren.
Cloud-basierte Plattform
DeepSeek-V2 kann auch über Cloud-basierte KI-Dienstleister genutzt werden, die in Zusammenarbeit mit DeepSeek gehostete Modellinferenz anbieten. Diese Plattformen bieten skalierbare Lösungen für Unternehmen, die KI nutzen möchten, ohne sich um die Infrastruktur kümmern zu müssen. Informationen zu Partnerunternehmen und Cloud-Integrationen von Drittanbietern finden Sie auf der DeepSeek-Website.
Bewertungsergebnisse
DeepSeek-V2 übertraf seine Vorgänger und andere Konkurrenzmodelle in mehreren Benchmarks für englische, chinesische, code- und mathematikbezogene Aufgaben. Im Vergleich zu Modellen mit über 67 Milliarden Parametern zeigt DeepSeek-V2 (MoE-236B) deutliche Verbesserungen. Es erreichte 78,5 im MMLU-Benchmark, DeepSeek-V1 (Dense-67B) erzielte 71,3 und liegt damit nahe an LLaMA3 70B mit 78,9. Ähnlich erzielte DeepSeek-V2 beim BBH-Benchmark 78,9, was eine deutliche Steigerung gegenüber den 68,7 von DeepSeek-V1 darstellt und mit den 81,0 von LLaMA3 70B gleichauf liegt.
In chinesischen Bewertungen zeigte DeepSeek-V2 eine herausragende Leistung und erzielte 81,7 bei C-Eval und 84,0 bei CMMLU, was deutlich über den Werten von DeepSeek-V1 mit 66,1 bzw. 70,8 liegt. In code-basierten Bewertungen wie HumanEval und MBPP erzielte DeepSeek-V2 48,8 bzw. 66,6 und zeigte damit eine stetige Verbesserung gegenüber DeepSeek-V1 mit 45,1 bzw. 57,4. Bei mathematischen Aufgaben erzielte DeepSeek-V2 79,2 bei GSM8K und 43,6 bei allgemeinen mathematischen Aufgaben, was eine deutliche Verbesserung gegenüber den 63,4 und 18,7 von DeepSeek-V1 darstellt.
Bei Modellen mit weniger als 16B zeigt DeepSeek-V2-Lite (MoE-16B) einen deutlichen Vorteil gegenüber vergleichbaren Modellen. Dies ist auf die Verwendung der MLA+MoE-Architektur zurückzuführen, die sowohl DeepSeek 7B (Dense) als auch DeepSeekMoE 16B übertrifft. Im MMLU-Benchmark erreichte es 58,3, DeepSeekMoE 16B 45,0 und DeepSeek 7B 48,2. Im BBH-Benchmark erreichte DeepSeek-V2-Lite 44,1, während DeepSeek 7B und DeepSeekMoE 16B mit 39,5 bzw. 38,9 hinterherhinkten.
In der chinesischen Bewertung erzielte DeepSeek-V2-Lite 60,3 bei C-Eval und 64,3 bei CMMLU und übertraf damit sowohl DeepSeek 7B als auch DeepSeekMoE 16B und behauptete seine Spitzenposition. Auch bei den Codierungs-Benchmarks zeigte es deutliche Verbesserungen und erzielte 29,9 bei HumanEval und 43,2 bei MBPP, was seine überlegene Leistung bei Softwareentwicklungsaufgaben unter Beweis stellt. Bei mathematischen Aufgaben hat DeepSeek-V2-Lite mit 41,1 Punkten bei GSM8K erhebliche Fortschritte erzielt. Dies ist ein großer Sprung nach vorne im Vergleich zu DeepSeek 7B mit 17,4 Punkten und DeepSeekMoE 16B mit 18,8 Punkten. In der allgemeinen Mathematik erzielte es 17,1 Punkte und übertraf damit die niedrigeren Ergebnisse früherer Versionen.
DeepSeek-V2-Chat-Modell
Das DeepSeek-V2-Chat-Modell hat in mehreren Bereichen erhebliche Leistungsverbesserungen gezeigt und dabei hervorragende Fähigkeiten im Bereich Sprachverständnis, Codierung und mathematischem Denken unter Beweis gestellt. Im Vergleich zu anderen groß angelegten Chat-Modellen erzielte DeepSeek-V2 Chat (SFT) beim MMLU-Benchmark 78,4 Punkte und übertraf damit DeepSeek-V1 Chat (71,1) und lag dicht hinter LLaMA3 70B Instruct (80,3). Die durch verstärktes Lernen verbesserte Version, DeepSeek-V2 Chat (RL), erzielte eine Punktzahl von 77,8 und behielt damit ihr hohes Niveau im Sprachverständnis bei. Im BBH-Benchmark erzielte DeepSeek-V2 Chat (SFT) eine Punktzahl von 81,3 und übertraf damit DeepSeek-V1 Chat (71,7) und sogar LLaMA3 70B Instruct (80,1). DeepSeek-V2 Chat (RL) konnte unterdessen eine hohe Punktzahl von 79,7 halten.
In chinesischen Bewertungen erzielte DeepSeek-V2 Chat (SFT) 80,9 Punkte bei C-Eval und 82,4 Punkte bei CMMLU und übertraf damit DeepSeek-V1 Chat (65,2 bzw. 67,8) deutlich. Die Version mit verstärktem Lernen setzte diesen Trend fort und erzielte 78,0 bei C-Eval und 81,6 bei CMMLU, wodurch ihre Fähigkeiten zum Verstehen und Verarbeiten chinesischer Texte weiter gestärkt wurden. Bei Codierungsaufgaben erzielte DeepSeek-V2 Chat (SFT) 76,8 bei HumanEval und 70,4 bei MBPP, während sich die RL-Version auf 81,1 bzw. 72,0 verbesserte. In LiveCodeBench verbesserte sich die Leistung von DeepSeek-V2 Chat (SFT) auf 28,7, und das RL-verbesserte Modell erreichte 32,5 und übertraf damit frühere DeepSeek-Versionen.
Bei mathematischen Aufgaben erzielte DeepSeek-V2 Chat (SFT) 90,8 bei GSM8K und übertraf damit DeepSeek-V1 Chat (84,1) deutlich und demonstrierte hervorragende Problemlösungsfähigkeiten. Die RL-verbesserte Version erreichte 92,2 und zeigte damit eine weitere Verbesserung. In allgemeinen Mathematik-Benchmarks erzielte DeepSeek-V2 Chat (SFT) 52,7 und die RL-Version 53,9, wobei beide DeepSeek-V1 Chat (32,6) deutlich übertrafen.
In kleinen Chat-Modellen zeigte DeepSeek-V2-Lite 16B Chat (SFT) im Vergleich zu früheren Versionen in verschiedenen Benchmarks eine überlegene Leistung. Es erreichte 55,7 im MMLU-Benchmark, 49,7 im DeepSeek 7B Chat und 47,2 im DeepSeekMoE 16B Chat. Beim BBH-Benchmark erreichte es 48,1 und übertraf damit kleinere Modelle. Bemerkenswert ist auch die Leistung bei chinesischen Benchmarks mit 60,1 bei C-Eval und 62,5 bei CMMLU, womit es die Ergebnisse früherer Modelle übertraf.
Bei Codierungsaufgaben erzielte DeepSeek-V2-Lite 16B Chat (SFT) 57,3 bei HumanEval und 45,8 bei MBPP und übertraf damit frühere Versionen deutlich. Bei mathematischen Aufgaben erzielte es 72,0 bei GSM8K und übertraf damit DeepSeek 7B Chat und DeepSeekMoE 16B Chat um fast 10 Punkte. Darüber hinaus erzielte es in der allgemeinen Mathematik 27,9 und übertraf damit frühere Modelle deutlich.
Das DeepSeek-V2-Chat-Modell, insbesondere das auf verstärktem Lernen basierende Modell, setzt neue Leistungsmaßstäbe in der KI-gesteuerten Sprachverarbeitung, den Codierungsfähigkeiten und dem mathematischen Denken und demonstriert damit seine Überlegenheit gegenüber früheren Versionen und Konkurrenzmodellen.

DeepSeek-V3
DeepSeek-V3 ist ein fortschrittliches MoE-Sprachmodell (Mixture-of-Experts), das die Grenzen der natürlichen Sprachverarbeitung erweitert. Seine groß angelegte Architektur und innovativen Trainingstechniken optimieren die Recheneffizienz und liefern gleichzeitig eine außergewöhnliche Leistung.
DeepSeek-V3 verwendet den Mixture-of-Experts (MoE)-Ansatz und verfügt über insgesamt 671 Milliarden Parameter, wobei pro Token nur 370 Milliarden Parameter aktiviert werden. Diese selektive Aktivierung ermöglicht eine effiziente Nutzung der Rechenressourcen und eine hohe Leistung.
Dieses Modell integriert Multi-Head Latent Attention (MLA) und verbessert damit seine Fähigkeit, komplexe Muster in Daten zu erfassen. Diese Verbesserung ermöglicht ein tieferes Verständnis komplexer Abfragen und eine verfeinerte Textgenerierung.
Eine der innovativen Funktionen von DeepSeek-V3 ist sein zusätzlicher verlustfreier Lastenausgleichsmechanismus. Dieser ermöglicht eine faire und effektive Verteilung der Rechenlast ohne zusätzliche Verlustfunktionen und sorgt so für ein stabileres und effizienteres Training.
Während herkömmliche Modelle einen Single-Token-Vorhersageansatz verwenden, setzt DeepSeek-V3 auf eine Multi-Token-Vorhersagestrategie. Dieser Ansatz verbessert die Verarbeitungsgeschwindigkeit und die Gesamtleistung des Modells erheblich.
Training und Leistung
DeepSeek-V3 wurde auf einem großen mehrsprachigen Korpus mit 14,8 Billionen hochwertigen Tokens trainiert. Dieser Datensatz besteht hauptsächlich aus Englisch und Chinesisch, wobei der Schwerpunkt auf Mathematik- und Programmierdaten liegt. Durch dieses umfassende Training kann das Modell in verschiedenen Bereichen, darunter natürliches Sprachverständnis, logisches Denken und Codegenerierung, hervorragende Leistungen erzielen.
Mit einer Architektur aus 61 Schichten und einer maximalen Kontextlänge von 128.000 Tokens kann DeepSeek-V3 lange Inhalte nahtlos verarbeiten. Benchmark-Bewertungen zeigen, dass dieses Modell Konkurrenten wie Llama 3.1 und Qwen 2.5 übertrifft und Ergebnisse erzielt, die mit GPT-4o und Claude 3.5 Sonnet vergleichbar sind.
Zugänglichkeit und Lizenzierung
DeepSeek-V3 ist Open Source, wobei sowohl der Code als auch die Modellgewichte öffentlich verfügbar sind. Das Modell wird unter der MIT-Lizenz für den Code veröffentlicht, während die Modellgewichte unter einer speziellen Lizenzvereinbarung verwaltet werden, um eine verantwortungsvolle Nutzung zu gewährleisten.
DeepSeek Coder
DeepSeek Coder wurde mit 2 Billionen Tokens in mehr als 80 Programmiersprachen vortrainiert, um ein umfassendes Verständnis verschiedener Codierungsmuster zu gewährleisten. Es bietet verschiedene Modellgrößen, darunter 1,3 Milliarden, 5,7 Milliarden, 6,7 Milliarden und 33 Milliarden, um unterschiedlichen Rechen- und Anwendungsanforderungen gerecht zu werden.
Mit einer Fenstergröße von 16K unterstützt DeepSeek Coder die Vervollständigung und das Ausfüllen von Code auf Projektebene und verbessert so seine Fähigkeit, umfangreiche Codestrukturen zu verstehen und zu generieren. Als eines der fortschrittlichsten Open-Source-Codemodelle ist DeepSeek Coder sowohl für Forschungszwecke als auch für den kommerziellen Einsatz verfügbar und macht damit fortschrittliche Technologien zur Codegenerierung zugänglicher.
So verwenden Sie DeepSeek Coder
DeepSeek Coder ist ein fortschrittliches Tool zur Codegenerierung, -vervollständigung und -ausfüllung, das auf KI basiert. Befolgen Sie die folgenden Schritte, um es zu installieren und effektiv zu nutzen.
Systemanforderungen
- Hardware: Wir empfehlen die Verwendung einer leistungsstarken GPU, insbesondere für große Modelle.
- Software: Stellen Sie sicher, dass Python 3.8 oder höher auf Ihrem System installiert ist.
Installieren Sie die erforderliche Software
- Python: Laden Sie Python von der offiziellen Website herunter und installieren Sie es.
- Git: Installieren Sie Git von der offiziellen Website.
Richten Sie eine virtuelle Umgebung ein
Öffnen Sie das Terminal oder die Eingabeaufforderung.
- Navigieren Sie zum Projektverzeichnis: cd /path/to/your/project
- Erstellen Sie eine virtuelle Umgebung: python -m venv deepseek-env
- Aktivieren Sie die virtuelle Umgebung.
- Windows: deepseek-env\Scripts\activate
- macOS/Linux: source deepseek-env/bin/activate
Laden Sie das gewünschte Modell herunter
Wählen Sie die Modellgröße entsprechend den Fähigkeiten Ihres Systems aus.
- 1,3-Milliarden-Modell: Geeignet für Systeme mit begrenzten Ressourcen.
- 5,7-Milliarden-Modell: Erfordert moderate Ressourcen.
- 6,7-Milliarden-Modell: Erfordert höhere Rechenleistung.
- 33-Milliarden-Modell: Bietet die beste Leistung, erfordert jedoch erhebliche Ressourcen.
Laden Sie das Modell mit dem im Repository bereitgestellten Skript herunter.
DeepSeek Coder ausführen
Verwenden Sie zum Ausführen des Modells den entsprechenden Befehl. Beispiel für die Ausführung des 6,7-Milliarden-Modells: python run_model.py –model deepseek-coder-6.7b
Testen Sie das Modell
Geben Sie eine Code-Eingabeaufforderung ein, um mit DeepSeek Coder zu interagieren. Beispiel:

Weitere
Ausführliche Informationen und zusätzliche Funktionen finden Sie im GitHub-Repository von DeepSeek Coder.
Leistung von DeepSeek Coder
DeepSeek hat DeepSeek Coder anhand verschiedener Benchmarks im Bereich der Codierung evaluiert. Die Ergebnisse zeigen, dass DeepSeek-Coder-Base-33B eine deutlich bessere Leistung erzielt als bestehende Open-Source-Code-LLMs. Im Vergleich zu CodeLlama-34B erzielt es Leistungsverbesserungen von 7,9 %, 9,3 %, 10,8 % und 5,9 % bei HumanEval Python, HumanEval Multilingual, MBPP und DS-1000. Bemerkenswert ist, dass DeepSeek-Coder-Base-7B das gleiche Leistungsniveau wie CodeLlama-34B erreicht hat. Darüber hinaus übertraf das DeepSeek-Coder-Instruct-33B-Modell nach der Anweisungsoptimierung GPT-3.5-turbo auf HumanEval und erzielte die gleichen Ergebnisse wie GPT-3.5-turbo auf MBPP.
Das DeepSeek Coder-Modell zeigte beim HumanEval-Benchmark sowohl für mehrsprachige Basismodelle als auch für anweisungsoptimierte Modelle eine hervorragende Leistung. Unter den Basismodellen belegte DeepSeek-Coder-Base-33B mit einer Durchschnittsbewertung von 50,3 % den ersten Platz und übertraf damit alle anderen Open-Source-Mehrsprachmodelle. Es erzielte die höchste Genauigkeit in Python (56,1 %), C++ (58,4 %), Java (51,9 %) und JavaScript (55,3 %). Das kleinere DeepSeek-Coder-Base-6.7B zeigte mit einer Durchschnittsbewertung von 44,7 % ebenfalls gute Ergebnisse und erzielte hervorragende Ergebnisse in C++ (50,3 %) und TypeScript (49,7 %). DeepSeek-Coder-MQA-Base-5.7B hingegen erzielte eine Punktzahl von 41,3 % und DeepSeek-Coder-Base-1.3B 28,3 %, was die skalierbare Leistungssteigerung mit zunehmender Modellgröße widerspiegelt.

Im Befehlsanpassungsmodell verbesserte DeepSeek-Coder-Instruct-33B die Leistung deutlich und erzielte eine beeindruckende durchschnittliche Genauigkeit von 69,2 %. Damit übertrifft es GPT-3.5-Turbo (64,9 %) und kommt nahe an GPT-4 (76,5 %) heran, wobei die Genauigkeit in Python (79,3 %), C++ (68,9 %) und JavaScript (73,9 %) besonders hoch ist. Die 6,7-Milliarden-Version von DeepSeek-Coder-Instruct erzielte ebenfalls eine sehr hohe Punktzahl von 66,1 %, während die 1,3-Milliarden-Version 48,4 % erreichte, was die Wirksamkeit der Anweisungsoptimierung über verschiedene Modellgrößen hinweg belegt.
Insgesamt zeigt das DeepSeek-Coder-Modell eine Leistung auf dem neuesten Stand der Technik unter den Open-Source-Code-LLMs, wobei die an die Anweisungen angepasste Version Ergebnisse erzielt, die mit proprietären Modellen wie GPT-3.5-Turbo und GPT-4 konkurrieren können.
Anwendungen des DeepSeek-Modells
Die Vielseitigkeit des DeepSeek-Modells macht es für eine Vielzahl von Anwendungen in der Praxis geeignet.
- Chatbots und virtuelle Assistenten: Verbesserung des Kundensupports und der Benutzerinteraktionen.
- KI-gestützte Codegenerierung: Unterstützung von Entwicklern bei der Softwareentwicklung und Fehlerbehebung.
- Automatische Erstellung von Inhalten: Generierung hochwertiger Artikel, Berichte und Zusammenfassungen.
- Lösung mathematischer Probleme: Unterstützung von Bildungswerkzeugen und Forschungsanwendungen.
Warum DeepSeek-R1 in den Vereinigten Staaten Alarm schlägt
Die Veröffentlichung von DeepSeek-R1 hat in den Vereinigten Staaten erhebliche Besorgnis ausgelöst und zu einem Ausverkauf von Technologieaktien geführt. Am Montag, dem 27. Januar 2025, eröffnete der Nasdaq Composite Index mit einem Minus von 3,4 %, wobei Nvidia um 17 % fiel und seine Marktkapitalisierung um etwa 60 Milliarden US-Dollar sank.
Das Aufkommen von DeepSeek hat in den Vereinigten Staaten aus den folgenden Hauptgründen mehrere große Bedenken ausgelöst:
Kostenstörung
DeepSeek behauptet, das R1-Modell für weniger als 6 Millionen US-Dollar entwickelt zu haben. Dies entspricht nur einem Bruchteil der Milliarden Dollar, die große US-Technologieunternehmen in KI investiert haben. Die niedrigen Entwicklungskosten und der erschwingliche Preis stellen eine direkte Bedrohung für die Geschäftsmodelle von US-KI-Unternehmen wie OpenAI dar.
Technologische Fortschritte trotz US-Vorschriften
Die Vereinigten Staaten haben strenge Exportbeschränkungen für leistungsstarke KI-Beschleunigerchips und GPUs nach China verhängt. DeepSeek hat jedoch gezeigt, dass es möglich ist, auch ohne Zugang zu den neuesten US-Technologien modernste KI zu entwickeln.
Herausforderung für das US-KI-Geschäftsmodell
Im Gegensatz zu den proprietären und kostenpflichtigen KI-Diensten von OpenAI verfolgt DeepSeek ein Open-Source-Modell, das kostenlos verfügbar ist. Dies schwächt die auf Abonnements basierende Einnahmequelle, die die US-KI-Branche dominiert.
Geopolitische Bedenken
Die Fortschritte von DeepSeek stärken die KI-Fähigkeiten Chinas und bedrohen die technologische Überlegenheit der USA. Der einflussreiche Tech-Investor Marc Andreessen hat diese Situation mit den Fortschritten der Sowjetunion im Weltraumrennen in den 1950er Jahren verglichen und sie als „Sputnik-Moment“ der KI bezeichnet.
Der rasante Aufstieg von DeepSeek verdeutlicht die sich wandelnde globale KI-Landschaft, verschärft den Wettbewerb und verstärkt die wirtschaftlichen und strategischen Bedenken der USA.
Fazit
DeepSeek ist führend im Bereich der KI-Innovation und bietet leistungsstarke Modelle, die die Grenzen der Effizienz und Effektivität erweitern. Mit ihrer hochmodernen Architektur und überragenden Benchmark-Leistung werden die Modelle von DeepSeek Branchen revolutionieren, die auf künstliche Intelligenz angewiesen sind. Ob für Forschung, Programmierung oder die Erstellung von Inhalten – die leistungsstarken Modelle von DeepSeek bieten robuste Lösungen für eine Vielzahl von KI-gesteuerten Anwendungen.
Häufig gestellte Fragen
Wie groß ist das Modell von DeepSeek?
DeepSeek bietet mehrere KI-Modelle in verschiedenen Größen an. DeepSeek-R1 verwendet eine Mixture of Experts (MoE)-Architektur mit 671 Milliarden Parametern und aktiviert 37 Milliarden während der Inferenz. DeepSeek-Coder wurde für Codierungsaufgaben entwickelt und hat einen Parameterbereich von 1 bis 33 Milliarden. Janus Pro hingegen ist ein Modell zur Bilderzeugung, das in Versionen mit 1 und 7 Milliarden Parametern erhältlich ist.
Ist DeepSeek AI kostenlos nutzbar?
Ja, DeepSeek AI-Modelle sind Open Source und kostenlos nutzbar. Die Premium-Version ist ein Abonnementmodell und unterscheidet sich von ChatGPT, das ebenfalls auf Abonnementbasis betrieben wird.
Wie erreicht DeepSeek trotz Beschränkungen für in den USA hergestellte Chips eine so hohe Leistung?
DeepSeek hat fortschrittliche KI-Modelle unter Verwendung alternativer Rechenressourcen entwickelt, ohne Zugang zu in den USA hergestellten Hochleistungs-KI-Chips wie dem H100 von Nvidia.
Wie sind die Preise von DeepSeek-R1 und DeepSeek-V3 im Vergleich?
DeepSeek-V3 bietet eine bessere Kosteneffizienz als DeepSeek-R1, mit einem Input-Token-Preis von 0,14 US-Dollar pro Million Token im Vergleich zu 0,55 US-Dollar pro Million Token für DeepSeek-R1. Ebenso liegt der Preis pro Ausgabetoken für DeepSeek-V3 bei 0,28 US-Dollar pro 1 Million Token und damit deutlich unter den 2,19 US-Dollar pro 1 Million Token für DeepSeek-R1.
Wie schneidet DeepSeek-Coder im Vergleich zu den Code-Interpretern GitHub Copilot oder ChatGPT ab?
DeepSeek-Coder unterstützt mehrere Programmiersprachen und kann wie GitHub Copilot effizienten Code generieren, legt jedoch Wert auf Open-Source-Zugänglichkeit.
Ist DeepSeek besser als ChatGPT?
Die Wahl zwischen DeepSeek und ChatGPT hängt von Ihren spezifischen Anforderungen ab. DeepSeek zeichnet sich aufgrund seiner Genauigkeit bei technischen Aufgaben wie Codierung und Mathematik aus. ChatGPT eignet sich aufgrund seiner Vielseitigkeit und seines breiten Funktionsumfangs besser für kreative und dialogorientierte Anwendungen.
Gibt es bei DeepSeek AI Einschränkungen hinsichtlich der Inhalte wie bei ChatGPT?
Ja, DeepSeek wendet strenge Moderationsrichtlinien gemäß den chinesischen Vorschriften an, insbesondere in Bezug auf politisch sensible Themen.

